掌握 Python 分布爬虫的数据一致性秘诀
Python 分布爬虫在数据处理中至关重要,其中数据一致性的保证更是关键所在。
在当今数字化时代,数据的价值不言而喻,而 Python 分布爬虫作为获取大量数据的有效手段,如何确保其获取的数据具有一致性,成为了开发者们必须攻克的难题。
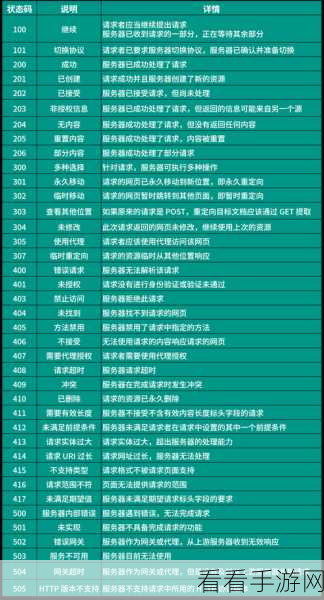
要实现 Python 分布爬虫的数据一致性保证,首先需要明确数据一致性的概念和重要性,数据一致性指的是在分布式环境中,多个爬虫节点获取的数据在逻辑上的一致性和准确性,这不仅关系到数据的质量,更直接影响到后续的数据分析和应用效果。
合理的任务分配和调度策略是保证数据一致性的基础,在分布爬虫系统中,需要根据各个节点的性能和网络状况,合理地分配爬虫任务,避免重复抓取和数据遗漏,通过有效的调度机制,及时协调各个节点的工作进度,确保数据采集的完整性和一致性。
数据存储和同步机制也是关键环节,选择合适的数据存储方式,如分布式数据库或分布式文件系统,能够有效地存储和管理大量的爬虫数据,建立可靠的数据同步机制,确保各个节点之间的数据能够及时更新和共享,避免数据不一致的情况发生。
错误处理和恢复机制也是不可或缺的一部分,在爬虫过程中,不可避免会遇到各种错误,如网络故障、服务器响应异常等,需要建立完善的错误处理机制,能够及时发现和处理错误,并在出现故障时能够快速恢复爬虫任务,保证数据采集的连续性和一致性。
持续的监控和优化是保证数据一致性的长效手段,通过对爬虫系统的实时监控,及时发现数据不一致的情况,并分析原因,采取相应的优化措施,不断提升分布爬虫的数据一致性保证能力。
Python 分布爬虫的数据一致性保证是一个综合性的工作,需要从多个方面入手,采用合理的技术和策略,才能确保获取到高质量、一致的数据,为后续的数据分析和应用提供有力支持。
文章参考来源:相关技术文档及行业研究报告。
