Python Scrapy 爬虫编写秘籍,从入门到精通
Python 的 Scrapy 框架为我们提供了强大的爬虫编写能力,如果您想要在数据采集的世界中畅游,掌握 Scrapy 爬虫的编写技巧是必不可少的。
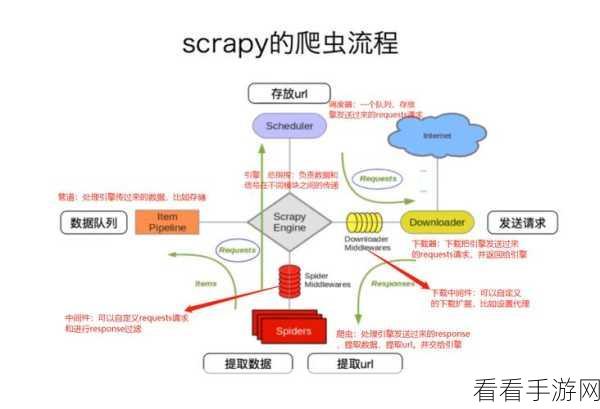
Scrapy 是一个基于 Python 的开源网络爬虫框架,它具有高度的灵活性和可扩展性,使用 Scrapy 编写爬虫,可以高效地抓取网页数据,并对数据进行处理和存储。
要开始编写 Scrapy 爬虫,首先需要安装 Scrapy 框架,可以通过 pip 命令轻松完成安装,安装完成后,就可以创建一个新的 Scrapy 项目。
在项目中,需要定义爬虫类,爬虫类中包含了对网页的请求、数据的提取和处理逻辑,通过设置起始 URL 以及定义回调函数,来控制爬虫的抓取流程。

数据提取是爬虫的核心环节,Scrapy 提供了多种选择器,如 XPath 和 CSS 选择器,帮助我们从网页中准确地提取所需的数据。
抓取到的数据需要进行处理和存储,可以将数据保存为文件,如 CSV 格式,也可以存储到数据库中,以便后续的分析和使用。
在实际编写过程中,还需要注意处理反爬虫机制、设置合理的请求间隔以及处理异常情况等,只有充分考虑这些因素,才能编写出稳定、高效的 Scrapy 爬虫。
掌握 Python Scrapy 爬虫的编写,将为您打开获取大量有价值数据的大门,助力您在数据分析和应用的道路上迈出坚实的一步。
参考来源:Python 官方文档、相关技术论坛及个人实践经验。
