深度剖析,Hive Hash 与 Range Partitioning 的优劣大揭秘
在当今的数据处理领域,Hive Hash 和 Range Partitioning 是两种常见的数据分区方式,它们各有特点,在不同的场景中发挥着重要作用。
Hive Hash 分区通过对指定列进行哈希计算,将数据均匀分布到不同的分区中,这种方式能够有效地提高数据查询的并行度,尤其适用于数据分布较为随机,且没有明显范围特征的情况,其优势在于可以快速定位到所需的数据分区,减少不必要的扫描。
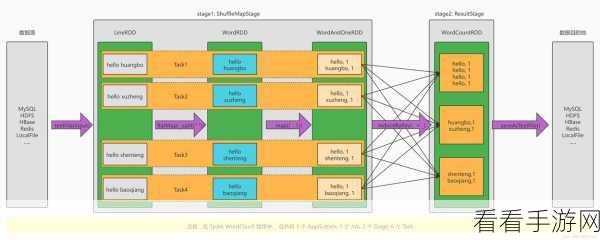
Range Partitioning 则是根据指定列的值的范围来划分分区,这使得在处理具有明显范围特征的数据时,如按照时间、价格等,能够更有针对性地进行查询和管理,通过将数据按照特定范围分组,可以提高查询的效率,特别是在涉及范围查询和分区裁剪的场景中。
Hive Hash 分区也存在一些局限性,当数据分布不均匀或者列的哈希值计算不够合理时,可能会导致某些分区数据量过大或过小,影响查询性能。
而 Range Partitioning 在处理数据范围变化频繁的情况时,可能需要频繁地调整分区范围,增加了管理的复杂性。
在实际应用中,选择使用 Hive Hash 还是 Range Partitioning ,需要综合考虑数据的特点、查询需求以及系统资源等因素。
如果数据的分布较为均匀且没有明显的范围特征,Hive Hash 分区可能是更好的选择,但如果数据具有明显的范围特征,且经常需要进行范围查询,Range Partitioning 则更能发挥其优势。
深入了解 Hive Hash 与 Range Partitioning 的特点和适用场景,能够帮助我们在数据处理中做出更加明智的决策,从而提高系统的性能和效率。
文章参考来源:行业技术文档及相关数据处理实践经验。
