掌握 ClickHouse 在 Kafka 中的配置秘籍,轻松提升性能
在当今数字化的时代,数据处理和分析的需求日益增长,ClickHouse 作为一款高性能的列式数据库管理系统,与 Kafka 的结合使用能够为企业带来更强大的数据处理能力,要实现两者的完美配置并非易事,其中蕴含着诸多技巧和要点。
Kafka 作为分布式消息队列,在数据传输和处理方面发挥着关键作用,而 ClickHouse 则以其出色的查询性能和数据压缩能力备受青睐,当它们协同工作时,正确的配置是确保系统高效运行的基础。

配置 ClickHouse 在 Kafka 中的相关参数时,需要对两者的特性有深入的理解,要关注数据的格式转换,确保 Kafka 中的数据能够被 ClickHouse 准确识别和处理,还需考虑数据的批量导入和实时消费,以平衡系统的性能和资源消耗。
对于数据的分区和副本设置也至关重要,合理的分区策略可以提高数据查询的效率,而适当的副本数量则能增强系统的可靠性和容错能力。
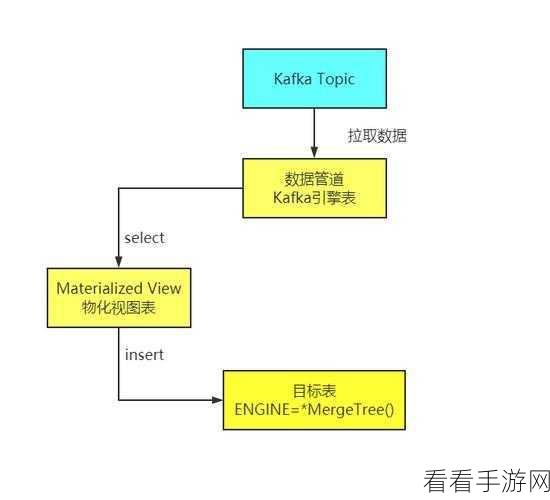
在进行配置的过程中,还应根据实际业务需求和系统的负载情况进行优化调整,不断地测试和监控系统的性能指标,及时发现并解决可能出现的问题。
要想充分发挥 ClickHouse 在 Kafka 中的优势,就必须精心配置各项参数,结合实际情况进行优化,从而为企业的数据分析和业务决策提供有力支持。
参考来源:相关技术文档和实践经验总结。
仅供参考,您可以根据实际需求进行修改和完善。
