探究 Flink 集成 Hive 于数据同步的实效性
Flink 与 Hive 的集成在数据同步领域一直备受关注,这种集成到底有没有效果呢?
要弄清楚 Flink 集成 Hive 在数据同步中的有效性,我们需要先了解 Flink 和 Hive 各自的特点,Flink 是一个分布式的流处理框架,以其出色的实时处理能力和高容错性而闻名,Hive 则是基于 Hadoop 的数据仓库工具,擅长处理大规模的离线数据。
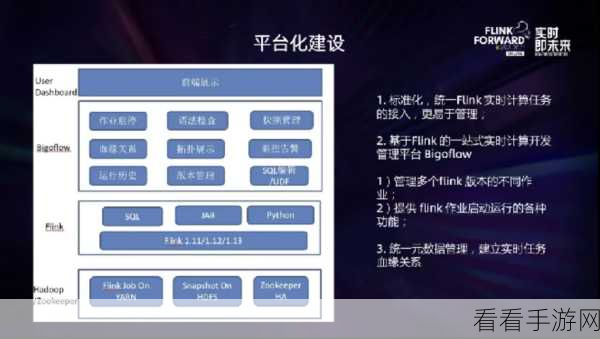
当 Flink 与 Hive 集成时,能够实现优势互补,Flink 可以利用 Hive 的存储和查询能力,对大规模数据进行高效处理,Hive 也能借助 Flink 的实时特性,提升数据的时效性。
在实际应用中,Flink 集成 Hive 并非一帆风顺,可能会面临数据格式转换的问题,不同的数据类型在两个系统之间的转换需要精心处理,否则容易导致数据错误,系统的配置和优化也是关键,不合理的配置可能无法充分发挥集成的优势,甚至影响数据同步的效率。

为了确保 Flink 集成 Hive 在数据同步中的有效性,我们需要注意以下几点,要对数据进行充分的预处理,确保数据的质量和格式符合要求,根据业务需求合理调整系统的配置参数,以达到最佳的性能,要对集成后的系统进行持续监控和优化,及时发现并解决可能出现的问题。
Flink 集成 Hive 在数据同步中具有一定的有效性,但需要我们在实践中不断探索和优化,才能充分发挥其优势,实现高效的数据同步。
文章参考来源:相关技术论坛及官方文档。
