Python Scrapy 爬虫调试秘籍大公开
在当今数字化时代,数据的获取和处理变得愈发重要,而 Python Scrapy 爬虫作为一种强大的数据采集工具,其调试过程却让许多开发者感到困扰,就让我们一同深入探索 Python Scrapy 爬虫的调试之道。
中心句:Python Scrapy 爬虫调试对开发者来说具有一定难度。
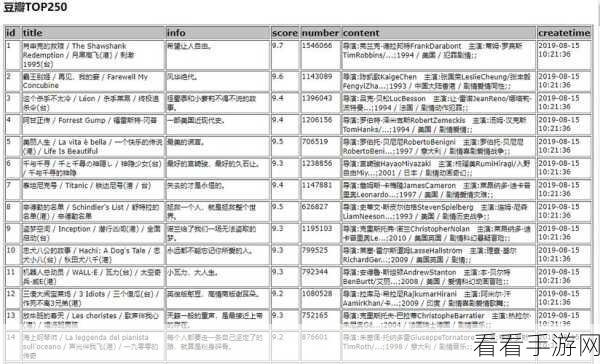
要成功调试 Python Scrapy 爬虫,首先需要对其基本架构和工作原理有清晰的理解,Scrapy 框架由引擎、调度器、下载器、爬虫、项目管道等多个组件构成,引擎负责控制整个系统的数据流,调度器管理请求队列,下载器负责获取网页内容,爬虫则负责解析网页并提取数据,项目管道用于对提取的数据进行后续处理,只有明白了这些组件的协同工作方式,才能在调试时迅速定位问题所在。
中心句:理解 Python Scrapy 爬虫的基本架构和工作原理是调试的基础。
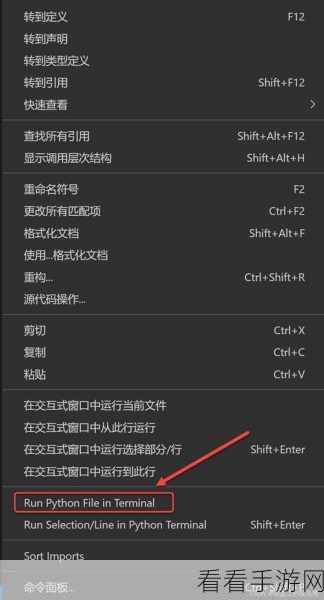
在调试过程中,仔细检查爬虫代码中的规则和选择器是关键的一步,确保选择器能够准确地匹配到所需的数据元素,并且规则的定义没有错误,要注意处理可能出现的异常情况,例如网页结构发生变化、网络连接中断等,通过设置合理的异常处理机制,可以让爬虫在遇到问题时能够优雅地应对,而不是直接崩溃。
中心句:检查爬虫代码中的规则和选择器,处理异常情况是调试的关键步骤。
合理利用 Scrapy 提供的日志功能能够为调试提供极大的帮助,通过查看日志信息,可以了解爬虫的运行状态、请求和响应的详情,以及可能出现的错误提示,根据这些日志信息,能够快速判断问题出在哪个环节,从而有针对性地进行修复和优化。
中心句:利用 Scrapy 的日志功能有助于快速定位调试中的问题。
还需要注意的是,测试数据的选择也会影响调试的效果,尽量选择具有代表性的数据进行测试,包括正常情况和可能出现异常的情况,这样可以更全面地检验爬虫的稳定性和适应性,确保在实际应用中能够应对各种复杂的场景。
中心句:选择具有代表性的测试数据对调试效果至关重要。
Python Scrapy 爬虫的调试并非一蹴而就,需要开发者耐心细致,综合运用多种方法和技巧,只有不断实践和总结经验,才能让爬虫更加稳定高效地运行,为我们获取所需的数据提供有力的支持。
参考来源:相关 Python 技术文档及开发经验总结。
仅供参考,您可以根据实际需求进行调整和修改。
