Python 爬虫与反爬虫的智斗秘籍
在当今数字化的时代,Python 爬虫与反爬虫的较量日益激烈,对于开发者和数据分析师来说,掌握有效的爬虫与反爬虫技巧至关重要。
爬虫技术可以帮助我们快速获取大量有价值的数据,但同时也面临着反爬虫机制的挑战,反爬虫机制旨在保护网站的正常运行和数据安全,防止恶意爬虫的侵扰,如何在这场技术的博弈中巧妙应对呢?
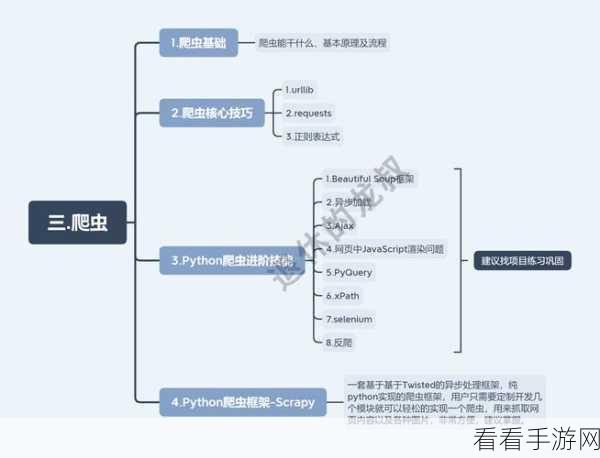
要理解 Python 爬虫与反爬虫的关系,我们需要先明确它们的定义和作用,Python 爬虫是通过编写程序自动获取网页数据的一种技术手段,而反爬虫则是网站为了阻止这种自动获取行为而采取的一系列措施。
在实际操作中,Python 爬虫需要应对各种反爬虫策略,比如常见的验证码验证、IP 封锁、访问频率限制等,为了突破这些限制,爬虫开发者需要运用多种技术手段,使用代理 IP 来切换访问的 IP 地址,模拟正常用户的访问行为,设置合理的访问间隔等。
反爬虫一方也在不断升级他们的防御手段,他们会通过分析访问请求的特征,如请求头、User-Agent 等,来识别爬虫行为,还会运用机器学习算法对访问模式进行监测和预警。
对于 Python 爬虫开发者来说,要时刻关注反爬虫技术的更新,不断优化自己的爬虫策略,也要遵守法律法规和道德规范,确保爬虫行为的合法性和合理性。
Python 爬虫与反爬虫的斗争是一场持续的技术较量,只有不断学习和创新,才能在这场博弈中取得优势。
参考来源:相关技术论坛及专业书籍。
