Kafka 单节点处理大数据的能力探秘
Kafka 作为一种流行的分布式消息队列系统,其在大数据处理领域的应用备受关注,Kafka 单节点是否能够应对大数据的挑战呢?
Kafka 单节点在处理大数据时存在一定的局限性,单节点的处理能力有限,无法与分布式架构相比,在面对海量数据的涌入时,可能会出现性能瓶颈,导致数据处理的延迟增加,单节点的容错性较差,一旦该节点出现故障,可能会导致数据丢失或处理中断,影响整个系统的稳定性和可靠性。
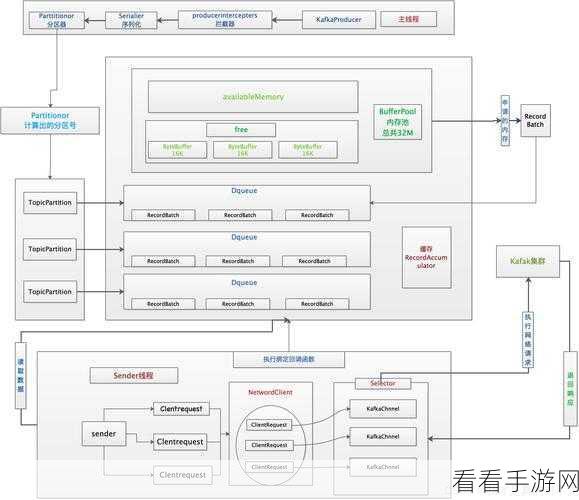
在某些特定的场景下,Kafka 单节点也并非完全不能处理大数据,如果数据量相对较小,且对处理实时性和容错性要求不高,单节点的 Kafka 可以作为一种简单有效的解决方案,一些小型企业或个人项目,数据规模有限,单节点的 Kafka 能够满足基本需求,同时降低系统的复杂性和成本。
要评估 Kafka 单节点处理大数据的可行性,需要综合考虑多个因素,数据量的大小、处理的实时性要求、系统的容错能力以及成本预算等都是关键的考量点,只有在充分了解这些因素的基础上,才能做出明智的决策,选择最适合的大数据处理方案。
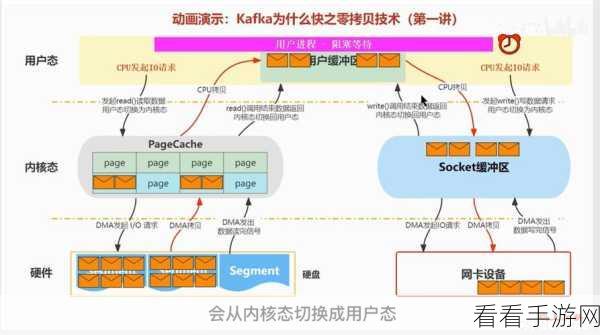
参考来源:相关技术论坛及官方文档
仅供参考,希望能对您有所帮助。
