Hive Collect 处理大数据的能力究竟如何?
Hive Collect 是一款在大数据处理领域备受关注的工具,它能否真正有效地处理大数据,成为了众多用户心中的疑问。
Hive Collect 具有一系列独特的特性和功能,为大数据处理提供了一定的可能性,其设计理念旨在应对大规模数据的存储、分析和处理需求,但要评估它处理大数据的能力,需要从多个方面进行考量。
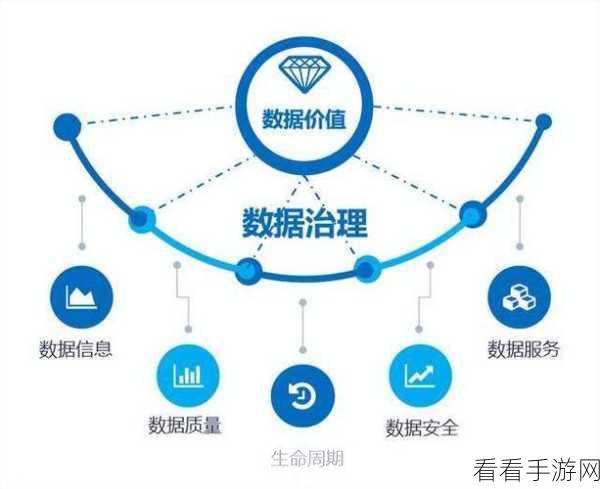
Hive Collect 的数据存储架构是一个关键因素,它采用了分布式的存储方式,能够将数据分散存储在多个节点上,从而提高数据的存储容量和访问效率,这种架构为处理海量数据奠定了基础。
Hive Collect 的数据处理算法和优化策略也对其处理大数据的能力产生重要影响,它具备多种数据处理算法,能够根据不同的数据类型和处理需求选择合适的算法,以提高处理效率,优化策略能够减少数据处理过程中的冗余操作和资源浪费。
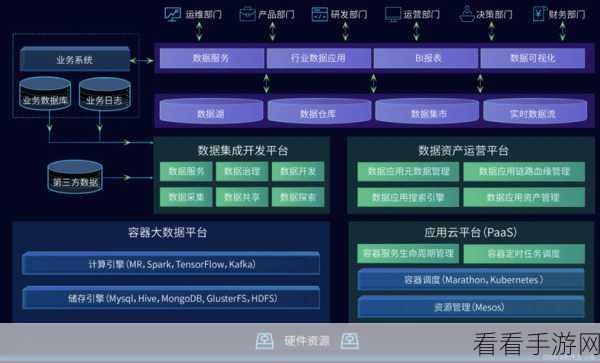
Hive Collect 的扩展性也是不容忽视的一点,在面对不断增长的数据量和处理需求时,它能够方便地进行横向扩展,增加计算和存储资源,以满足业务的发展需要。
Hive Collect 在处理大数据时也并非毫无挑战,数据的一致性和准确性保障需要特别关注,在分布式环境下,数据的同步和一致性维护可能会面临一些困难。
Hive Collect 在处理大数据方面具有一定的潜力和优势,但也需要用户在实际应用中根据具体需求进行合理的配置和优化,以充分发挥其能力。
参考来源:相关技术文档和行业研究报告。
