在当今数字化时代,数据的实时分析对于企业和组织的决策制定至关重要,Flink 和 Kafka 作为强大的工具,在数据实时处理领域发挥着关键作用,本文将深入探讨它们如何协同工作,实现高效的数据实时分析。
中心句:数据的实时分析在当今数字化时代极其重要。
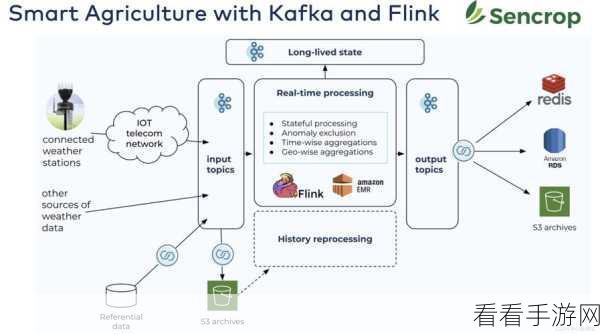
Flink 是一个出色的流处理框架,具有出色的性能和强大的功能,它能够以低延迟和高吞吐的方式处理数据流,为实时分析提供了坚实的基础。
中心句:Flink 是性能出色且功能强大的流处理框架。
Kafka 则是一个分布式的消息队列系统,能够可靠地存储和传递大量的数据,其分区和副本机制确保了数据的高可用性和容错性。
中心句:Kafka 是能可靠存储和传递大量数据的分布式消息队列系统。
当 Flink 与 Kafka 结合时,二者优势互补,Flink 可以从 Kafka 中读取数据,并进行实时处理和分析,Flink 处理后的数据也可以写入 Kafka,供其他系统进一步使用。
中心句:Flink 与 Kafka 结合时优势互补。
在配置方面,需要正确设置 Flink 的数据源和数据输出,以及 Kafka 的主题、分区等参数,以确保数据的流畅传输和处理。
中心句:正确配置是实现 Flink 与 Kafka 数据流畅传输和处理的关键。
在实际应用中,还需要考虑数据的格式转换、异常处理等问题,以保证系统的稳定性和准确性。
中心句:实际应用中要考虑多种问题以保证系统的稳定性和准确性。
掌握 Flink 和 Kafka 进行数据实时分析的方法和技巧,将为您的业务带来更高效的决策支持和更出色的用户体验。
文章参考来源:相关技术文档和行业实践经验。
仅供参考,您可以根据实际需求进行调整和修改。