在当今数字化时代,数据处理的实时性成为了众多应用场景的关键需求,而 Stream Kafka 作为一种强大的数据处理工具,为实现数据的实时处理提供了有力支持。
Stream Kafka 之所以能在数据实时处理领域大放异彩,得益于其独特的架构和功能特性,它采用了分布式的设计,能够高效地处理大规模的数据流量,其消息队列机制保证了数据的可靠传输和有序处理。

Stream Kafka 进行数据实时处理的过程中,数据的摄入环节至关重要,它能够快速接收来自各种数据源的实时数据,并将其转化为可供后续处理的格式,在数据处理阶段,Stream Kafka 利用丰富的处理算子和函数,对数据进行过滤、转换、聚合等操作,以满足不同的业务需求,而数据的输出环节则确保处理后的数据能够准确无误地送达目标系统或应用。
为了更好地运用 Stream Kafka 进行数据实时处理,需要合理配置相关参数,调整缓冲区大小、优化消息发送和接收的频率等,以提升系统的性能和效率,对数据的分区和副本策略进行精心设计,能够增强系统的容错性和扩展性。
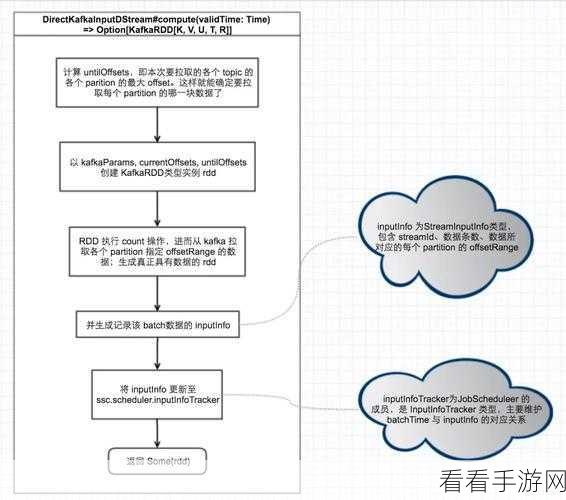
监控和优化也是确保 Stream Kafka 数据实时处理效果的重要环节,通过实时监控系统的各项指标,如吞吐量、延迟、资源利用率等,能够及时发现潜在的问题,并采取相应的优化措施。
Stream Kafka 在数据实时处理方面具有巨大的优势和潜力,只要我们深入了解其原理和机制,合理运用相关技术和策略,就能充分发挥其作用,为各种业务场景提供高效、准确的数据处理服务。
参考来源:相关技术文档及行业研究报告。