在当今数字化的时代,数据实时计算成为了众多企业和开发者关注的焦点,而 Flink 和 Kafka 这两个强大的工具,为实现高效的数据实时处理提供了有力支持。
Flink 作为一款出色的流处理框架,具备强大的实时计算能力,它能够快速处理源源不断的数据流,并在短时间内得出准确的结果,Kafka 则是分布式消息队列中的佼佼者,能够有效地存储和传递数据。
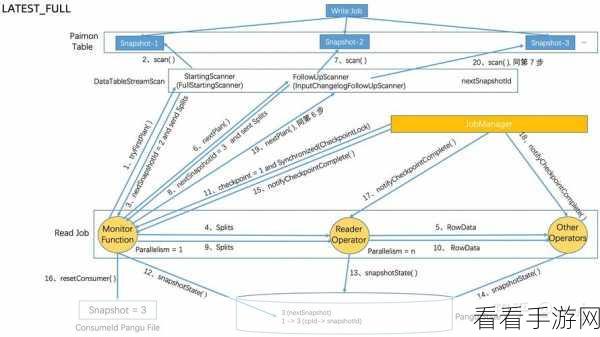
如何让 Flink 和 Kafka 协同工作,发挥出最大的效能呢?
第一步,要做好环境搭建,确保 Flink 和 Kafka 的安装和配置正确无误,这是后续工作的基础。
第二步,数据的接入与处理至关重要,合理地将数据从 Kafka 引入到 Flink 中,并进行有效的清洗、转换和计算。
第三步,关注性能优化,通过调整参数、优化代码等方式,提高整个数据处理流程的效率和稳定性。
第四步,监控与容错不能忽视,实时监控系统的运行状态,及时发现并处理可能出现的错误,保障数据计算的连续性和准确性。
要实现 Flink 和 Kafka 的完美结合,实现数据实时计算,需要从多个方面入手,精心设计和优化整个流程,只有这样,才能充分发挥它们的优势,为业务发展提供有力的数据支持。
文章参考来源:相关技术文档及行业实践经验。