Stream Kafka 在数据处理中扮演着重要角色,而如何实现其数据实时过滤更是关键所在。
Kafka 作为一种强大的分布式消息队列,在数据处理领域应用广泛,Stream Kafka 的数据实时过滤功能更是备受关注,数据实时过滤能够帮助我们快速获取所需信息,提高数据处理效率。
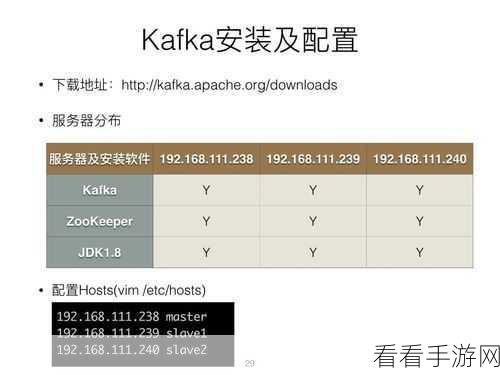
要实现 Stream Kafka 的数据实时过滤,我们需要先明确一些关键概念,了解数据的流向和处理流程,清楚各个组件之间的协同工作方式,这有助于我们在后续的操作中更加得心应手。
掌握合适的过滤策略至关重要,根据数据的特点和需求,选择恰当的过滤条件,按照特定的字段值、数据范围或者时间戳等进行筛选。

合理配置过滤参数也是不可忽视的环节,包括设置缓冲区大小、过滤的并发度以及数据的延迟处理等,这些参数的优化能够显著提升过滤效果。
在实际操作中,还需要不断测试和优化过滤方案,通过观察数据的处理结果,分析是否达到预期效果,及时调整策略和参数,以达到最佳的实时过滤性能。
Stream Kafka 的数据实时过滤并非一蹴而就,需要我们深入理解其原理,灵活运用各种策略和参数,并不断实践和改进,才能实现高效、准确的数据处理。
参考来源:相关技术文档及行业实践经验。