掌握 flink 与 kafka 数据异常处理的关键技巧
在当今数字化时代,数据处理成为了众多应用的核心环节,而 flink 和 kafka 作为常用的数据处理工具,如何应对其中的数据异常情况至关重要。
数据异常处理是保障数据质量和系统稳定运行的关键,当 flink 和 kafka 协同工作时,可能会出现各种各样的数据异常状况,比如数据丢失、数据重复、数据延迟等。
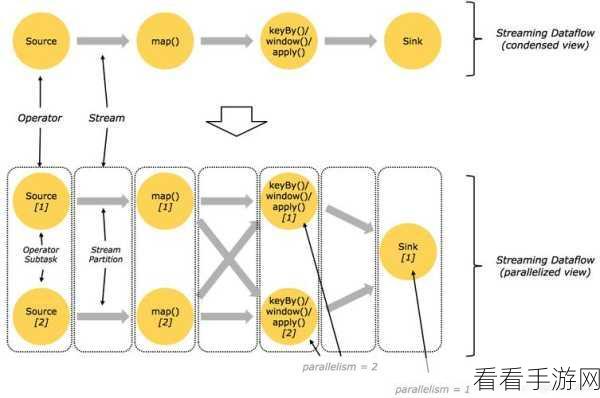
要有效地处理这些异常,我们需要深入了解 flink 和 kafka 的工作机制,Flink 具有强大的流处理能力,能够实时监测和处理数据,而 Kafka 则作为优秀的分布式消息队列,在数据传输和存储方面发挥着重要作用。
针对数据丢失的情况,我们需要检查数据源的稳定性,确保数据的完整输入,设置合适的容错机制,例如检查点和恢复机制,以便在出现故障时能够快速恢复数据。

对于数据重复的问题,要对数据进行去重处理,可以通过在 flink 中设置相应的算子,或者利用 kafka 的消息唯一标识来避免重复数据的产生和处理。
数据延迟则需要我们分析是由于网络原因、系统负载还是其他因素导致,优化系统配置、增加资源分配或者调整数据处理流程,都可能有助于解决数据延迟的问题。
熟练掌握 flink 和 kafka 的数据异常处理方法,能够让我们在数据处理工作中更加游刃有余,提升系统的稳定性和数据的准确性。
文章参考来源:相关技术文档及行业经验总结。
