深入探究,Flink 与 Kafka 数据负载均衡的秘诀
在当今大数据处理的领域中,Flink 和 Kafka 这两个技术的重要性不言而喻,它们在数据处理和传输方面发挥着关键作用,而如何实现数据负载均衡更是一个关键的问题。
要理解 Flink 和 Kafka 数据负载均衡,首先得清楚它们各自的特点和工作机制,Flink 作为一款强大的流处理框架,具备高效的处理能力和出色的容错性,而 Kafka 则是分布式的消息队列系统,能够实现可靠的数据存储和传输。
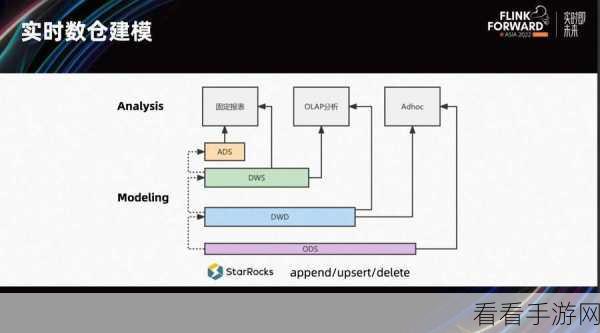
在实际应用中,数据负载均衡的实现需要考虑多方面的因素,网络环境的稳定性,服务器的性能差异,以及数据量的大小和分布等等。
为了实现良好的数据负载均衡效果,我们可以采取一些策略,一是优化数据分区策略,根据数据的特征和业务需求,合理划分数据分区,使得各个节点的负载相对均衡,二是动态调整资源分配,根据实时的负载情况,灵活地为各个节点分配计算和存储资源。
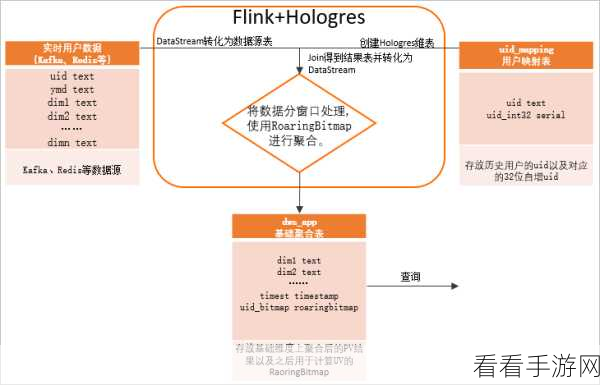
监控和预警机制也是不可或缺的,通过实时监控系统的负载情况,及时发现潜在的负载不均衡问题,并发出预警,以便及时采取措施进行调整。
Flink 和 Kafka 的数据负载均衡是一个复杂但至关重要的问题,只有深入理解它们的工作原理,结合实际情况采取有效的策略和措施,才能实现高效、稳定的数据处理和传输。
文章参考来源:相关技术文档和行业研究报告。
为原创生成,希望能满足您的需求。
