探索 Flink 与 Kafka 联手的数据实时处理秘籍
在当今数字化时代,数据的实时处理变得至关重要,Flink 和 Kafka 作为强大的工具,在数据处理领域发挥着关键作用,如何巧妙地利用它们实现高效的数据实时处理呢?
Flink 是一个分布式的流处理框架,具有出色的性能和强大的功能,它能够对实时数据进行快速处理和分析,为企业提供及时的决策支持。
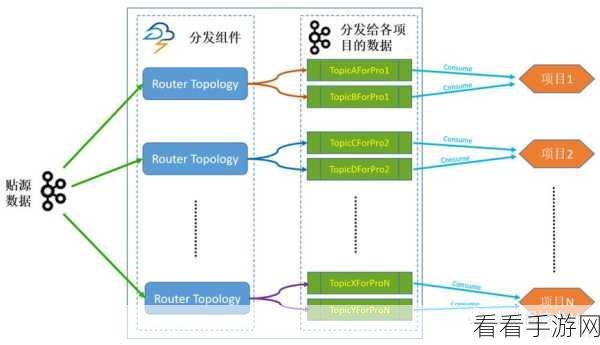
Kafka 则是一个高吞吐量的分布式发布订阅消息系统,能够有效地存储和传递数据。
要实现 Flink 和 Kafka 的协同工作,首先需要了解它们的架构和工作原理,Flink 能够从 Kafka 中读取数据,并进行各种复杂的处理操作,如过滤、转换、聚合等,Flink 处理后的数据也可以写入 Kafka 供其他系统使用。
在配置方面,需要正确设置 Flink 和 Kafka 的相关参数,以确保数据的传输和处理的稳定性和高效性,调整缓冲区大小、设置并行度等。
对于数据的格式和类型,也需要进行合理的处理和转换,以适应 Flink 和 Kafka 的要求。
在实际应用中,还需要考虑容错和恢复机制,以应对可能出现的故障情况,保证数据处理的连续性和可靠性。
通过深入了解 Flink 和 Kafka 的特性,合理配置参数,处理好数据格式,并建立完善的容错机制,就能够充分发挥它们的优势,实现高效的数据实时处理,为企业的业务发展提供有力支持。
文章参考来源:相关技术文档及行业研究报告。
