Stream Kafka 数据处理优化秘籍大揭秘
Stream Kafka 作为一种强大的数据处理工具,其优化工作至关重要,要实现高效的数据处理,需要从多个方面入手。
在数据处理的世界里,Stream Kafka 占据着重要的地位,如何对其进行优化以达到最佳性能,却是让许多开发者头疼的问题,优化 Stream Kafka 的数据处理,不仅能够提升系统的运行效率,还能为用户带来更流畅的体验。
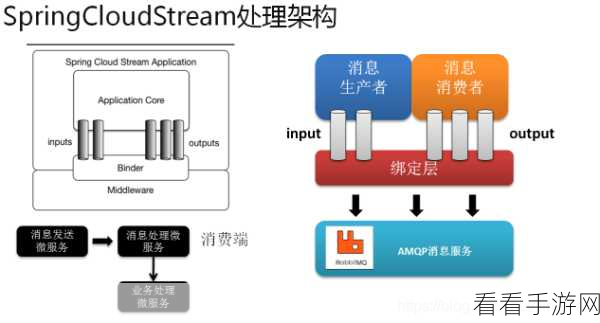
要优化 Stream Kafka 的数据处理,首先得关注数据的输入和输出,确保输入的数据质量良好,避免无效或错误的数据进入处理流程,对输出的数据进行合理的格式化和压缩,减少数据传输的开销。
合理配置资源也是关键的一环,根据实际的业务需求和数据量,调整 Kafka 集群的节点数量、内存分配和存储容量等参数,以充分发挥系统的性能。

数据分区策略同样不容忽视,通过合理划分数据分区,可以实现数据的均衡分布,提高并行处理能力,从而加快数据处理速度。
优化消费者和生产者的代码逻辑也是必不可少的,减少不必要的操作和重复计算,提高代码的执行效率。
监控和性能测试是持续优化的保障,实时监测系统的各项指标,如吞吐量、延迟、资源利用率等,根据测试结果及时调整优化策略。
Stream Kafka 的数据处理优化是一个综合性的工作,需要从多个角度进行考虑和实践,只有不断探索和优化,才能让 Stream Kafka 在数据处理领域发挥出更大的作用。
参考来源:相关技术论坛及专业书籍。
仅供参考,您可以根据实际需求进行调整。
