探秘 Kafka 顺序消息,一致性的保障秘籍
在当今数字化的时代,消息处理的准确性和一致性至关重要,而 Kafka 作为一种强大的消息中间件,其顺序消息的一致性保障更是备受关注。
Kafka 顺序消息一致性的实现并非偶然,而是通过一系列精心设计的机制和策略达成的,Kafka 利用分区(Partition)的概念来对消息进行分类和存储,每个分区都是一个有序的消息队列,这为保证消息的顺序性奠定了基础。
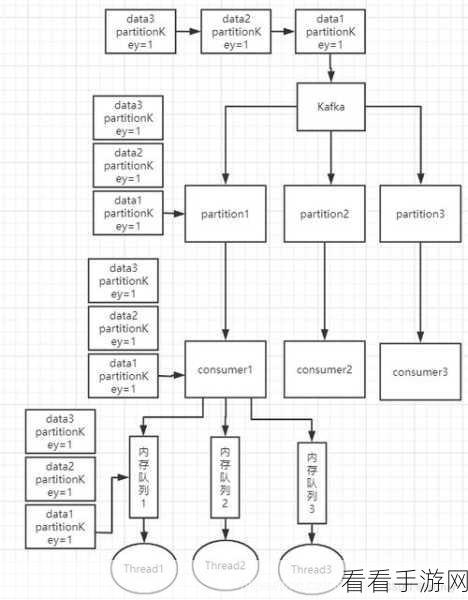
Kafka 还采用了副本机制(Replication)来增强数据的可靠性和一致性,当主副本出现故障时,从副本能够迅速接管,确保消息的处理不中断,从而维持了一致性。
Kafka 的生产者和消费者在处理消息时也遵循特定的规则,生产者在发送消息时,会将消息按照特定的顺序发送到对应的分区,而消费者在消费消息时,也会按照分区内的消息顺序进行处理,不会出现乱序的情况。
为了进一步确保一致性,Kafka 还引入了事务(Transaction)的支持,通过事务,可以将一系列的消息发送操作视为一个原子单元,要么全部成功,要么全部失败,避免了部分成功导致的数据不一致问题。
Kafka 顺序消息一致性的保障是一个综合性的工程,涉及到分区、副本、生产者和消费者的协同工作,以及事务的支持等多个方面,只有深入理解并合理运用这些机制,才能充分发挥 Kafka 在消息处理领域的强大优势,为各类应用提供稳定可靠的服务。
文章参考来源:Kafka 官方文档及相关技术论坛的讨论。
