Stream Kafka 处理海量数据的秘诀大揭秘
在当今数字化时代,数据量呈爆炸式增长,如何有效地处理大数据量成为了众多企业和开发者面临的重要挑战,Stream Kafka 作为一款强大的分布式消息队列系统,在处理大数据量方面有着出色的表现,让我们一起深入探索 Stream Kafka 处理大数据量的独特方法和技巧。
Stream Kafka 之所以能够应对大数据量的处理需求,关键在于其卓越的架构设计,它采用了分布式架构,将数据分散存储在多个节点上,实现了横向扩展,从而能够轻松应对不断增长的数据量。
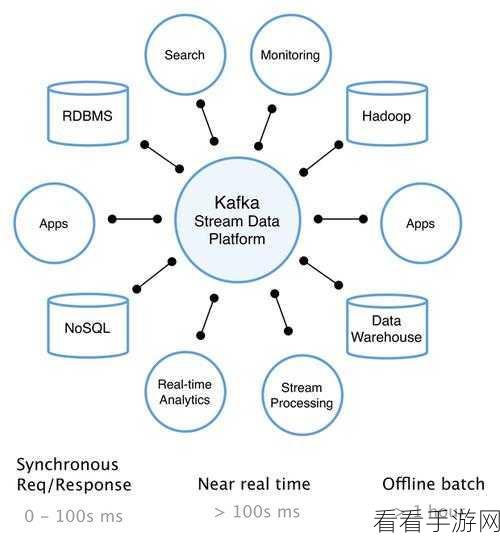
Stream Kafka 还具备高效的消息存储和检索机制,通过使用分段存储和索引技术,能够快速定位和读取所需的消息,大大提高了数据处理的效率。
合理的配置参数对于 Stream Kafka 处理大数据量也至关重要,调整缓冲区大小、消息批处理大小等参数,可以优化系统的性能,使其在处理大量数据时更加稳定和高效。
为了确保 Stream Kafka 能够持续稳定地处理大数据量,监控和优化也是必不可少的环节,实时监控系统的性能指标,如吞吐量、延迟等,及时发现并解决潜在的问题,能够保障系统的正常运行。
Stream Kafka 在处理大数据量方面展现出了强大的能力,但要充分发挥其优势,需要我们深入了解其架构、机制,合理配置参数,并做好监控和优化工作。
参考来源:相关技术文档及行业研究报告。
仅供参考,您可以根据实际需求进行调整和修改。
