探秘 Syslog Kafka 数据解析的奇妙之旅
在当今数字化的时代,数据的处理和分析变得至关重要,Syslog Kafka 作为一种常见的数据处理方式,其数据解析的过程充满了挑战与奥秘。
要理解 Syslog Kafka 数据解析,我们首先得明晰 Syslog 协议的特点和 Kafka 框架的工作原理,Syslog 协议是一种用于在网络中传递系统日志信息的标准协议,它定义了日志消息的格式和传输方式,而 Kafka 则是一个分布式的消息队列系统,能够高效地处理和存储大量的消息数据。
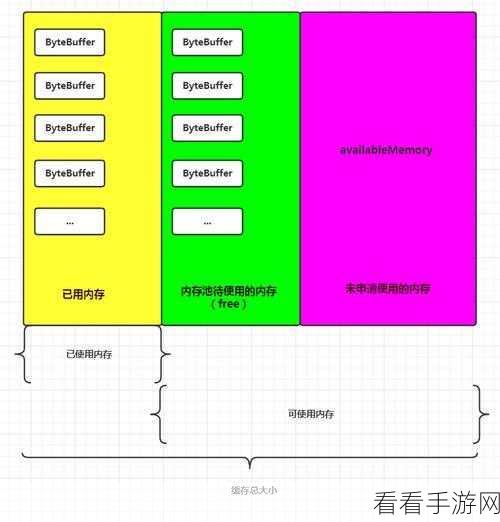
当 Syslog 数据进入 Kafka 后,数据解析的关键步骤就开始了,这需要对数据进行清洗和预处理,去除无效或重复的信息,提取出关键的字段和值,在这个过程中,运用合适的数据处理工具和算法至关重要。
数据格式的转换也是必不可少的一环,将 Syslog 数据的特定格式转换为适合后续分析和处理的通用格式,能够大大提高数据的可用性和可读性。
还需要建立有效的数据索引和分类机制,通过对数据进行分类和索引,可以快速定位和检索所需的数据,提高数据处理的效率。
在实际的应用场景中,根据不同的业务需求和数据特点,对 Syslog Kafka 数据解析进行优化和调整也是非常重要的,只有不断地优化和改进,才能更好地满足业务的需求,发挥数据的最大价值。
Syslog Kafka 数据解析是一个复杂但又充满魅力的领域,需要我们深入了解相关技术和原理,并不断实践和探索,才能在数据的海洋中找到宝贵的信息。
参考来源:相关技术文档及行业研究报告
