攻克 Hive Hash 数据倾斜难题的秘诀
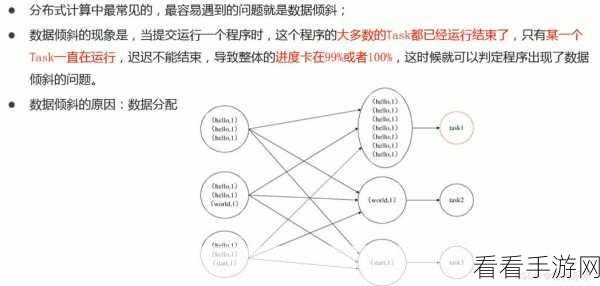
Hive Hash 数据倾斜一直是困扰众多开发者的难题,数据倾斜会导致任务执行效率低下,延长处理时间,甚至可能导致任务失败,如何有效地解决这一问题呢?
数据倾斜产生的原因多种多样,数据分布不均匀是常见的因素之一,某些键值的出现频率远远高于其他键值,导致处理这些键值的任务负载过重,表连接操作不当也可能引发数据倾斜,在连接大表和小表时,如果连接条件不合理,就容易造成数据倾斜,数据类型的不一致也可能成为诱因。
解决 Hive Hash 数据倾斜的方法众多,一种有效的方法是使用随机数进行打散,在进行数据处理前,为可能导致倾斜的键值添加随机数,从而使数据分布更加均匀,这样可以避免大量数据集中在少数几个节点上。
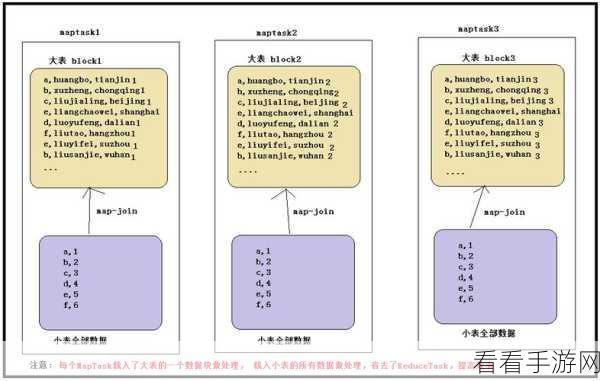
调整连接方式也是重要的手段,对于大表和小表的连接,可以采用 Map 端连接或者将小表广播到所有节点,以减少数据倾斜的可能性。
合理设置参数也能起到一定的作用,通过调整 Hive 的相关参数,如hive.groupby.skewindata 等,可以优化数据处理过程,缓解数据倾斜的影响。
在实际应用中,还需要根据具体的业务场景和数据特点,综合运用这些方法,找到最适合的解决方案,不断地进行测试和优化,以确保系统的性能和稳定性。
参考来源:相关技术文档及实践经验总结
