探究,Hive ClusterBy 在数据同步中的实际效果
在当今数字化的时代,数据同步成为了众多应用场景中的关键环节,而 Hive ClusterBy 这一技术在数据同步中是否有效,备受关注。
Hive ClusterBy 是 Hive 中的一种数据处理方式,它能够对数据进行分组和排序,在数据同步的过程中,它到底能发挥怎样的作用呢?

要了解 Hive ClusterBy 在数据同步中的有效性,我们需要先明确数据同步的需求和目标,不同的业务场景对于数据同步的准确性、实时性以及数据量的要求各不相同。
对于大规模的数据同步任务,Hive ClusterBy 可以通过优化数据的分布和排序,提高数据处理的效率,它能够将相似的数据聚集在一起,减少数据的读取和处理时间。
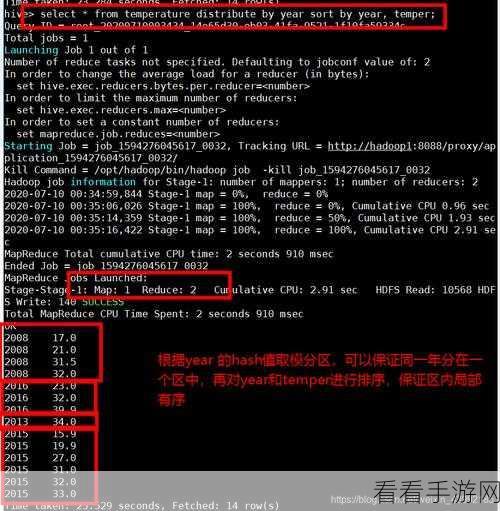
Hive ClusterBy 并非在所有情况下都是最佳选择,如果数据的分布本身就比较均匀,或者数据量较小,使用 Hive ClusterBy 可能并不会带来显著的性能提升,甚至可能增加额外的开销。
Hive ClusterBy 的配置参数也会对其在数据同步中的效果产生影响,合理设置相关参数,如分区数量、排序字段等,能够更好地发挥其优势。
在实际应用中,为了准确评估 Hive ClusterBy 在数据同步中的有效性,我们需要进行大量的测试和对比,通过不同的数据集、不同的业务场景以及不同的配置参数组合,来观察其性能表现。
Hive ClusterBy 在数据同步中是否有效,不能一概而论,需要根据具体的业务需求、数据特点以及系统配置来综合判断和评估,只有在合适的场景中正确使用,才能充分发挥其优势,为数据同步工作带来高效和可靠的支持。
文章参考来源:行业相关技术文档及实践经验总结。
