中国移动大模型在cvpr视觉领域顶级会议获得了:中国移动大模型在CVPR会议上斩获视觉领域新突破与荣誉
视觉领域主题生成的研究进展
大模型在计算机视觉中的应用
大模型技术正在推动计算机视觉(CV)领域的发展。这些模型通过深度学习和大量的数据训练,能够从图像中提取特征,实现物体识别、场景理解等任务。💡 近年来,各种预训练的大模型相继问世,包括Vision Transformer (ViT)、DETR等,为科研人员提供了强大的工具。
班级生成与内容创作
班级生成是一项利用AI进行自动化文本或内容生产的技术。在CV领域,这一技术使得复杂数据集的信息分析变得更加高效,通过解析图片及其相关信息,可以快速生成描述性文字。例如,使用深度学习算法对社交媒体上的图像进行分类,同时为每个类别创建出符合语义要求的文案。🖼️✨

数据驱动的方法论
现代计算机视觉依赖于海量标注数据以实现精准预测。然而,由于人工标注成本高昂,因此采用自监督和无监督方法成为解决方案之一。这类方法不仅提升了数据处理效率,还扩宽了可用的数据源,使得更多样本参与到训练过程中,从而丰富了最终输出结果🌍🔍。
自然语言处理结合 CV 的前景
自然语言处理(NLP)与计算机视觉(CV)的结合正创造新的可能性。当机器能同时理解图像和文本时,就可以发展出更高级别的人车互动系统,比如智能助手,它们能够根据用户上传的照片给出详细建议或反馈📷🤔。这种跨模态的信息融合是未来的发展方向。
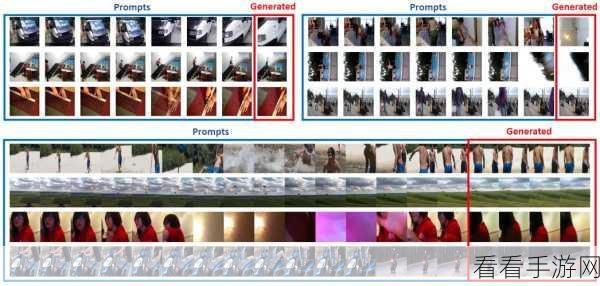
关键挑战与问题
尽管取得了一定成就,但仍面临诸多挑战,例如如何提高大规模视听模式下对小样本情况的适应能力,以及如何确保所生成内容的一致性和准确性。此外,对于隐私保护的问题也不容忽视,大规模采集个人图片需要遵循严格法规👁️🗨️⚖️。
应用案例分析
一些成功案例展示了这些技术在实际生活中的应用,比如用于电子商务的平台,通过分析产品图片并匹配相关评论,以便向消费者推荐最优选品。这样的创新带来了商业模式的新转型,有助于提升客户体验😊📈。
Q&A部分
Q: 如何评估一个AI产生作品的质量?
A: AI作品质量通常通过专业人士审查、一致性测试以及用户反馈来评估。同时,也会考虑上下文关联及逻辑连贯性的指标🎯.
Q: 在什么情况下选择使用自监督学习?
A: 当缺乏足够标签数据且希望充分挖掘未标注数据库潜力时,自监督学习是理想选择。这种方式能有效降低人力成本,提高建模效率🚀.
参考文献:1. "Exploring the Role of Large Models in Computer Vision";2. "Generative Techniques for Visual Data Synthesis";3. "Cross-modal Learning for Enhanced Text-Image Representation".


