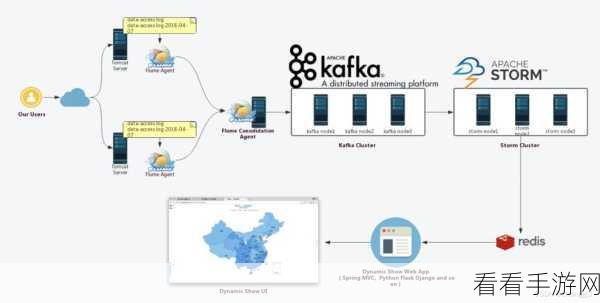
Flume插件扩展深度解析,揭秘其在Kafka集群中的高效支持。
在手游开发领域,数据的实时处理与传输至关重要,随着游戏用户量的不断增长,如何高效地收集、处理并存储这些数据,成为开发者们面临的一大挑战,Apache Flume作为一款分布式、可靠且可用的服务,用于高效地收集、聚合和移动大量日志数据,而Kafka则以其高吞吐量和低延迟的特性,成为众多手游数据流的首选,我们将深入探讨Flume插件扩展如何实现对Kafka集群的高效支持,为手游开发者们提供一份详尽的技术指南。

中心句:Flume与Kafka的结合,为手游数据实时处理提供强大支持。
Flume与Kafka的结合,为手游数据的实时处理与传输带来了革命性的变化,Flume能够收集来自不同源的数据,如游戏日志、用户行为数据等,并通过其强大的插件体系,将这些数据高效地传输到Kafka集群中,Kafka集群则以其分布式架构和高吞吐量的特性,确保数据能够实时、可靠地存储和传输,这种结合不仅提高了数据的处理效率,还降低了系统的延迟,为手游的实时数据分析与监控提供了有力保障。
中心句:Flume插件扩展的奥秘,揭秘其如何优化Kafka集群支持。
Flume插件扩展究竟是如何实现对Kafka集群的高效支持的呢?这主要得益于Flume的灵活插件体系和Kafka的客户端API,Flume提供了丰富的Source、Channel和Sink组件,开发者可以根据实际需求选择合适的组件进行组合,以实现数据的定制化收集与处理,Flume的Kafka Sink插件通过优化与Kafka客户端API的交互,实现了数据的高效传输,通过调整批量发送的大小、设置合理的重试机制等,Flume能够确保数据在传输过程中的稳定性和可靠性。
Flume还支持多种数据格式和序列化方式,如Avro、JSON等,这使得Flume能够轻松地将不同类型的数据转换为Kafka集群所能识别的格式,这种灵活性不仅提高了数据的兼容性,还为手游开发者提供了更多的选择空间,以满足不同场景下的数据处理需求。
中心句:实战案例分享,展示Flume插件在手游项目中的具体应用。
为了更好地理解Flume插件在手游项目中的具体应用,我们分享一个实战案例,某知名手游公司为了实时监控游戏运行状态和用户行为,采用了Flume与Kafka结合的数据处理方案,他们通过Flume收集游戏服务器产生的日志数据,并利用Flume的Kafka Sink插件将这些数据实时传输到Kafka集群中,随后,他们利用Kafka的消费者API,将数据实时推送到数据分析平台,进行实时分析和监控,这一方案不仅提高了数据的处理效率,还为游戏运营团队提供了及时、准确的数据支持,帮助他们更好地了解游戏运行状态和用户行为,从而做出更加精准的决策。
参考来源:基于Apache Flume和Kafka的日志收集与处理技术研究
最新问答:
1、问:Flume与Kafka结合使用时,如何确保数据的完整性和准确性?
答:Flume提供了事务性支持,确保在数据传输过程中数据的完整性和准确性,Kafka也提供了数据复制和容错机制,进一步提高了数据的可靠性。
2、问:在手游项目中,如何选择合适的Flume插件进行数据处理?
答:选择Flume插件时,需要根据项目的实际需求和数据类型进行综合考虑,对于游戏日志数据,可以选择Flume的TailSource插件进行收集;对于用户行为数据,则可以选择HTTPSource插件进行收集,还需要考虑插件的性能、稳定性和兼容性等因素。
3、问:Flume与Kafka结合使用时,如何优化数据传输性能?
答:优化数据传输性能可以从多个方面入手,如调整Flume的批量发送大小、设置合理的Kafka分区数、优化网络配置等,还可以利用Kafka的消费者API进行并行消费,进一步提高数据的处理效率。