探讨SFT与RLHF在手游AI领域的应用与演进
近年来,随着人工智能技术的飞速发展,手游行业也迎来了前所未有的变革,从早期的简单规则引擎到如今高度智能化的NPC(非玩家角色)交互,AI技术在手游中的应用日益广泛,SFT(Standard Fine-Tuning,标准微调)与RLHF(Reinforcement Learning with Human Feedback,基于人类反馈的强化学习)作为两种重要的AI技术,正逐步成为手游AI领域的新宠,本文将深入探讨SFT之后,为何RLHF成为手游AI发展的必然选择,并揭示其如何引领手游AI进入新纪元。
中心句:SFT技术的局限性
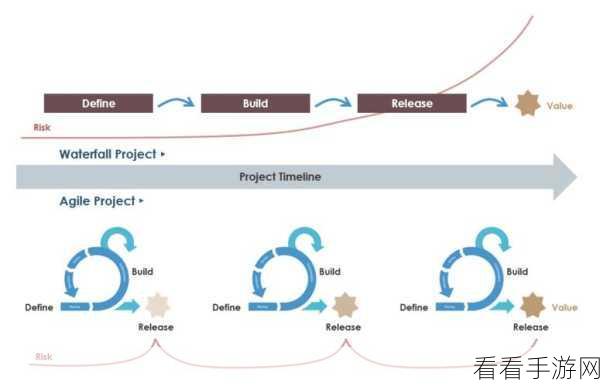
SFT技术,作为AI领域的一种基础微调方法,通过在大规模数据集上训练模型,再针对特定任务进行微调,以实现更高的性能,在手游中,SFT技术被广泛应用于NPC的行为模拟、对话生成等方面,随着玩家对游戏交互体验要求的不断提高,SFT技术的局限性逐渐显现,NPC的对话往往缺乏真实感和多样性,难以与玩家产生深入的互动,SFT模型在面对复杂多变的游戏场景时,往往难以做出合理的决策,导致游戏体验大打折扣。

中心句:RLHF技术的崛起与优势
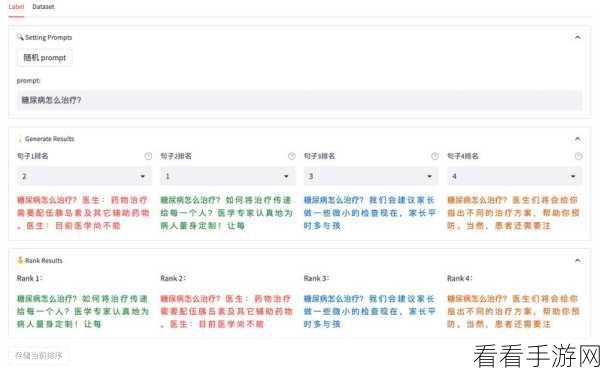
正是在这样的背景下,RLHF技术应运而生,与SFT不同,RLHF技术强调通过人类反馈来优化AI模型的行为,在训练过程中,模型会不断尝试各种行为,并根据人类提供的反馈(如奖励或惩罚)来调整其行为策略,这种基于人类反馈的学习方法,使得RLHF模型能够更准确地理解人类意图,从而生成更加自然、真实的对话和行为,在手游中,RLHF技术的应用意味着NPC将不再只是简单的脚本执行者,而是能够根据玩家的行为和反馈进行动态调整的智能体,这将极大地提升游戏的交互性和沉浸感,为玩家带来前所未有的游戏体验。
中心句:RLHF在手游中的具体应用案例
以某知名手游为例,该游戏引入了RLHF技术来优化NPC的对话和行为,在游戏中,玩家可以与NPC进行自由对话,并根据对话内容选择相应的行动,NPC会根据玩家的选择和反馈,动态调整其对话和行为策略,当玩家表现出对某个话题的兴趣时,NPC会主动展开相关话题的讨论;当玩家对某个任务感到困惑时,NPC会提供详细的指导和帮助,这种基于人类反馈的交互方式,使得游戏世界更加生动、有趣,也极大地提升了玩家的参与度和满意度。
中心句:RLHF技术的未来展望与挑战
尽管RLHF技术在手游AI领域展现出了巨大的潜力,但其发展仍面临诸多挑战,如何收集和处理大量的人类反馈数据,以确保模型的准确性和稳定性;如何平衡模型的复杂性和计算效率,以满足手游实时交互的需求;以及如何避免模型过度依赖人类反馈,导致缺乏自主创新能力等,随着技术的不断进步和算法的优化,相信RLHF技术将在手游AI领域发挥更加重要的作用,为玩家带来更加丰富、多样的游戏体验。
参考来源:
本文基于当前手游AI领域的发展趋势和技术动态进行撰写,参考了多家知名游戏公司和AI研究机构的最新研究成果和报告。
最新问答:
1、问:RLHF技术能否完全替代SFT技术在手游AI中的应用?
答:RLHF技术虽然具有诸多优势,但并不能完全替代SFT技术,两者各有千秋,应根据具体应用场景和需求进行选择和优化。
2、问:RLHF技术在手游中的应用是否会增加游戏开发成本?
答:短期内,RLHF技术的应用确实可能增加游戏开发成本,包括数据收集、模型训练等方面的投入,但长期来看,随着技术的成熟和普及,这些成本将逐渐降低,甚至可能带来更高的游戏收益。
3、问:玩家如何参与到RLHF技术的反馈过程中?
答:玩家可以通过游戏内的对话选择、行为反馈等方式参与到RLHF技术的反馈过程中,这些反馈数据将被用于优化AI模型的行为策略,从而提升游戏的交互性和沉浸感。